|
��_�i�d�C�E�d�q�n���ȏ��V���[�Y�j  ��_�̃G�b�Z���X  �F�������� �\�ʎq��_����ǂ���A�F���Ƃ��������ׂ��Í� (�P�s�{)  |
�����i���傤�ق���傤�A�G���g���s�[�Ƃ��j�́A��_�̊T�O�ŁA����ł����Ɓi���ہj���N�����ہA���ꂪ�ǂ�قNjN����ɂ�������\���ړx�ł���B�p�ɂɋN����ł����Ɓi���Ƃ��u�����l�����ށv�j���N���������Ƃ�m���Ă�����͂��������u���v�ɂ͂Ȃ�Ȃ����A�t�ɖő��ɋN����Ȃ��ł����Ɓi���Ƃ��u�l���������ށv�j���N����A����͂�葽���́u���v���܂�ł���ƍl������B���ʂ͂��̂ł����Ƃ��ǂꂾ���̏��������Ă��邩�̎ړx�ł���Ƃ��݂Ȃ����Ƃ��ł���B �Ȃ������ł����u���v�Ƃ́A�����܂ł��̂ł����Ƃ̋N����ɂ����i�m���j�����ɂ���Č��܂鏃���ɐ��w�I�ȗʂ̂��Ƃł���A���ꂪ�l�E�Љ�ɂƂ��Ăǂꂾ���Ӌ`�̂�����̂��Ƃ͖��W�ł���B���Ƃ��u���������ɓ��������v���ۂƁu���m���A�����ɓ��������v���ۂ́A�O�҂̕����L�Ӌ`�ȏ��Ɍ����邪�A���҂̏��ʂ͑S�������ł���i����������m���͏��^�������̂��Ƃł͒N�ł������ł��邩��j�B �I�����ʁi���ȃG���g���s�[�j�ƕ��Ϗ��ʁi�G���g���s�[�j���ꂼ��̂ł����Ƃ̏��ʂ����łȂ��A�����̂ł����Ƃ̏��ʂ̕��ϒl�������ʂƌĂԁB���҂���ʂ���ꍇ�ɂ́A�O�҂��I�������i���ȃG���g���s�[�Ƃ��j�A��҂����Ϗ����i�G���g���s�[�Ƃ��j�ƌĂԁB �I����������E���N����m����P(E)�Ƃ���Ƃ��A ���� E ���N���������Ƃ�m�炳�ꂽ������i�I���j����I(E) �� �ƒ�`����B �N����ɂ������ہi�����N�m�����Ⴂ���ہj�̏��ʂقǁA�l���傫���B �㎮���̑ΐ� (log) �̒�Ƃ��ĉ���I��ł��A���ʂ̒l���萔�{�ς�邾���Ȃ̂ŁA�{���I�ȍ��͂Ȃ����̂́A��Ƃ��Ă�2��I�Ԃ��Ƃ������B �ꂪ2�̏ꍇ�A�m����1 / 2n�ŋN���鎖�ۂ̏��ʂ�n�ł���B ���ϓI�Ӗ�����u�ɑ��Au�̑ΐ�logmu��m�i�@�ł�u�̌����ɂقړ������l��\���B���������āA�m��1 / u�ŋN���鎖�ۂ̏��ʂ́A�ق�u�̌����ɂȂ�B ���ʂ̉��@��A��B���Ɨ��Ȏ��ۂ̂Ƃ��A�uA��B���N����v�Ƃ������ۂ̏��ʂ́AA�̏��ʂ�B�̏��ʂ̘a�ł���B ���ʂɂ͉��@��������B�Ⴆ�A52���̃g�����v���疳��ׂ�1�������o���Ƃ������s���l����B�u���o�����J�[�h�̓n�[�g��4�ł���v�Ƃ������ۂ̏��ʂ́A�O�q�̒�`����log52 �ł���ƕ�����B�����ŁA�u���o�����J�[�h�̃X�[�g�̓n�[�g�ł���v�Ƃ������ۂƁu���o�����J�[�h�̐�����4�ł���v�Ƃ������ۂ̓���l����ƁA�O�҂̏��ʂ�log4�A��҂�log13 �ł���B���̗��҂̘a��log4 + log13 = log(4�~13) = log52 �ƂȂ�A�u���o�����J�[�h�̓n�[�g��4�ł���v�Ƃ������ۂ̏��ʂƓ������B����͒����I�v���ɍ��v����B ���Ϗ��ʁi�G���g���s�[�j�����A�䂪�L���W���ł���m����ԂƂ���B����̊m�����z P���^����ꂽ�Ƃ��A�e���� ��P���G���g���s�[�ƌĂԁi���Ϗ����A�V���m�������A���_�̃G���g���s�[�Ƃ��j�B �������A������P(A)=0�̂Ƃ��́AP(A)logP(A)
= 0�Ƃ݂Ȃ��B����� �܂��L���W��U��̒l�����m���ϐ�X���m�����zP�ɏ]���ꍇ�ɂ́AX���G���g���s�[��H(X)=H(P)�ɂɂ���Ē�߂�B���Ȃ킿�A
�G���g���s�[�͏�ɔ̒l�i�܂��͖�����j�����B �lx�Ay�����ꂼ��m���ϐ�X�AY�ɏ]���ꍇ�ɂ́A�g(x,y)���m���ϐ��Ƃ݂Ȃ���B���̊m���ϐ���(X,Y)�Ə������ɂ���ƁA�m���ϐ�(X,Y)�̃G���g���s�[�� �ɂȂ�B X,Y���݂��ɓƗ��Ȋm���ϐ��ł���ꍇ�ɂ́AH(X,Y)��H(X) + H(Y)�Ɉ�v����B�����A�S�̂̏���H(X,Y)�́A���ꂼ��̊m���ϐ��̏��ʂ̘a�ł���B �������AX��Y���݂��ɓƗ��ł͂Ȃ��ꍇ�́AH(X,Y)��H(X) + H(Y)�͈�v�����A�O�҂���҂̕����傫���l�ɂȂ�B���҂̏��ʂ̍������ݏ����ƌĂсA
�ŕ\���B���ݏ��ʂ͏�ɔ̒l�ɂȂ�B ����B�������Ă���Ƃ����������ɂ����鎖��A�������t�������� �ŕ\���B ����Ɋm���ϐ�Y���^����ꂽ�Ƃ��A�����t���G���g���s�[H(X | Y = b)��b�Ɋւ��镽�ϒl
����͂������t���G���g���s�[�ƌĂԁB �G���g���s�[�̊�{�I����
�R�C�������̗�����R�C���𓊂����Ƃ��ɕ\���o��m���� p�A�����o��m���� 1 - p �Ƃ���B���̃R�C���𓊂����Ƃ��ɓ����镽�Ϗ��ʁi�G���g���s�[�j�́A �ł���B�@ ���̊�f(p) = ? plogp ? (1 ? p)log(1 ? p)���G���g���s�[���ƌĂԁB
�}������ƕ�����悤�ɁAp = 0 �� p = 1 �ł� H �̓[���ł���B�܂�A�R�C���𓊂���O���痠�܂��͕\���o�邱�Ƃ��m���ɕ������Ă���Ƃ��ɓ����镽�Ϗ��ʂ́A�[���ł���BH ���ő�ɂȂ�̂� p = 1 / 2 �̂Ƃ��ł���A��ʂɂ��ׂĂ̎��ہi�ł����Ɓj�����m���ɂȂ�Ƃ��ɃG���g���s�[���ő�ɂȂ�B �A���n�̃G���g���s�[�����l�����m���ϐ�X�̊m�����x����p(x)�Ƃ���Ƃ��AX�̃G���g���s�[�� �ɂ���Ē�`����B X���L���W���ɒl�����m���ϐ��ł���ꍇ�ɂ́AX�̃V���m������H(X)����`�ł���BX��n�ʂ�̒l�����Ƃ��AH(X)��h(X)�́A
�����B �A���A������Un��n���W����̈�l���z�Ƃ���i���Ȃ킿H(Un) = logn�j�B Renyi�G���g���s�[�����A�䂪�L���W���ł���m����ԂƂ���BP������̊m�����z�Ƃ��A����̎����Ƃ���B
�ɂ���Ē�`����B �܂��A �ɂ���Ē�`����B �P��Renyi�G���g���s�[�ƌ������ꍇ��H2(P)���Ӗ����邱�Ƃ������B ����ɁA�m���ϐ�X���m�����zP�ɏ]���Ƃ��AH��(X)��H��(X) = H��(P)�ɂ���Ē�`����B Renyi�G���g���s�[�͈ȉ��̐��������F
���j�u�G���g���s�[�v�̊T�O��1865�N�Ƀ��h���t�E�N���E�W�E�X���M���V����́u�ϊ��v���Ӗ����錾�t���ꌹ�Ƃ��āA�M�͊w�ɂ�����C�̂̂����ԗʂƂ��ē��������B����͓��v�͊w�ł͔����I�ȏ�Ԑ��̑ΐ��ɔ�Ⴗ��ʂƂ��ĕ\�����B1929�N�ɂ̓��I�E�V���[�h���A�C�̂ɂ��Ă̏����ϑ��҂��l�����邱�ƂƓ��v�͊w�ɂ�����G���g���s�[�Ƃ̊Ԃɒ��ڂ̊W�����邱�Ƃ������A���� 1 �r�b�g�i1 �V���m���j�ƌĂԗʂ����v�͊w�� k ln 2 �ɑΉ�����Ƃ����W���Ă����B ���݂̏�_�ɂ�����G���g���s�[�̒��ڂ̓�����1948�N�̃N���[�h�E�V���m���ɂ����̂ŁA���̒����w�ʐM�̐��w�I���_�x�ŃG���g���s�[�̊T�O����_�ɉ��p�����B�V���m�����g�͓��v�͊w�ł��̊T�O�Ɗ֘A����T�O�����łɎg���Ă��邱�Ƃ�m�炸�ɂ��̒�`�ɓ��B���Ă������A���̖��̂��ǂ����ׂ������t�H���E�m�C�}���ɑ��k���A�t�H���E�m�C�}���̒ɂ���ăG���g���s�[�Ɩ��t����ꂽ�B �Ȃ��A�V���m���ȑO�ɂ������t�E�n�[�g���[��1928�N�ɁA�W��A�ɑ��� �P�����ʂ͖{���������̗ʂł���B�������A�ΐ��̒�Ƃ��ĉ���p�������ɂ���Ēl���قȂ�̂ŁC�P�ʂ�t���ċ�ʂ��Ă���B�O�q�̂悤�ɁA���ʂ͊m���̋t���������̊��Ғl�Ȃ̂ŁA�P�ʂ������̂���𗬗p����B���ׁ̈A�ΐ��̒�Ƃ���2�Ae�A10��I�Ƃ��̏��ʂ̒P�ʂ́A���ꂼ���r�b�g(bit)�A�i�b�g(nat)�A�f�B�b�g(dit)�ł���B �܂��A���̂Ƃ���嗬�ł͂Ȃ����̂́A1997�N�ɓ��{�H�ƋK�i JIS X 0016:1997�i����͍��ۋK�i ISO/IEC 2382-16:1996�ƈ�v���Ă���j�́A�����̗ʂ�\���P�ʂ�ʂɒ�߂Ă���B
�P�ʁu�V���m���v�A�u�n�[�g���[�v�̖��̂́A���ꂼ����ʂ̊T�O���Ă����N���[�h�E�V���m���A�����t�E�n�[�g���[�ɂ��ȂށB |

 �̑I������
�̑I������ 
 �ł��鎖�ɂ��B
�ł��鎖�ɂ��B �B
�B
 �ɂ���Ē�߂�B�m���ϐ�X���^����ꂽ���A���ہu
�ɂ���Ē�߂�B�m���ϐ�X���^����ꂽ���A���ہu ��a�Ɋւ��镽�ϒl�������t���G���g���s�[�Ƃ����A
��a�Ɋւ��镽�ϒl�������t���G���g���s�[�Ƃ����A



 �̂Ƃ��AP��degee
�̂Ƃ��AP��degee
 �̏ꍇ�ɂ́ARenyi�G���g���s�[��
�̏ꍇ�ɂ́ARenyi�G���g���s�[��
 ����������B
����������B
 ����������B�����ŁA
����������B�����ŁA �͊m�����z
�͊m�����z  ��
�� �����ꂼ��
�����ꂼ�� ����������m���Ƃ���B
����������m���Ƃ���B
 ����������B����
����������B���� ��min�G���g���s�[�Ƃ������B
��min�G���g���s�[�Ƃ������B  �Ƃ����ʂ��l�@���Ă���i�g
�Ƃ����ʂ��l�@���Ă���i�g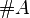 �h��A�̌����j�B
�h��A�̌����j�B